

Creating Your Virtual Agent
A fun adventure in learning how to craft a synthetic human to do your bidding

Last week I wrote a piece called “How to Think About A.I. in 2025.” The upshot of the post was how you will likely never really learn anything useful reading the news headlines because they are stuck in predictable buckets that really have nothing to do with you, the user. I proposed an alternative learning track including:
Finding a part of the larger field you are actually interested in.
Identifying real problems you can solve using A.I.
Developing a learning track by either taking courses or playing around with tools
For those with more advanced skills, identifying specific gaps or deficits you might address
I recently came across a new app called Hedra so it made sense to follow up last week’s post with some learning of my own. Hedra is an A.I. Video platform. It allows you to create virtual people through a combination of Natural Language Processing and Machine Vision. These two technologies combine to allow users to animate images in a lifelike fashion. It’s very similar to Synthesia. I spent a fair amount of time with Synthesia last year but could never really get it to where I felt 100% comfortable with the outputs. Synthesia’s avatars have significant “uncanny valley” issues. Synthesia is a great tool but I’d been left wanting more so I was excited to stumble on Hedra and give it a whirl.
Simple and Easy to Use
The first thing that stuck out was the simplicity of the layout. There are two basic elements - the audio and the image that turn into the video.
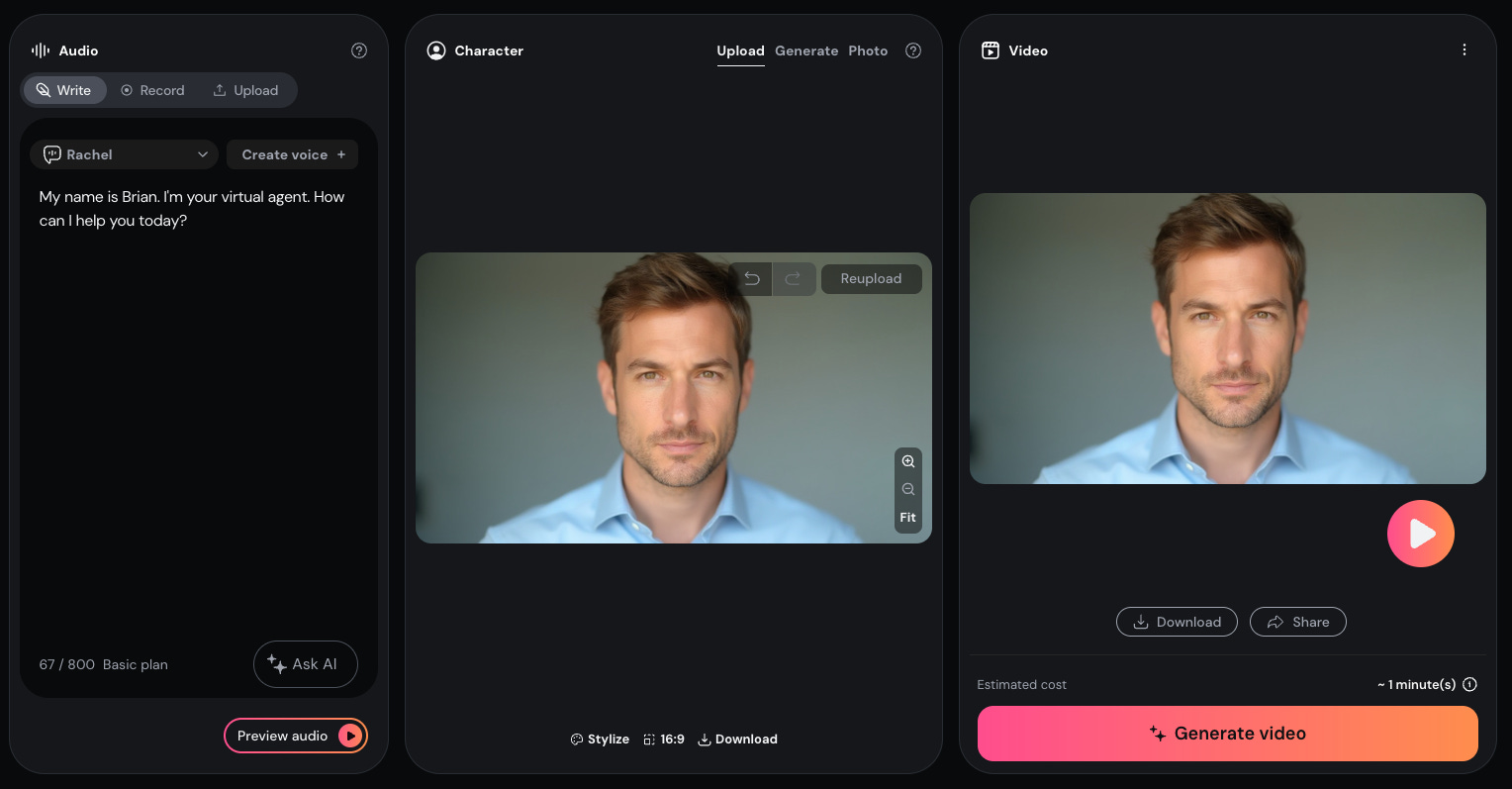
The application allows you to translate text to speech with a wide variety of pre-built voices. It also allows you to either upload a photo that it translates into video or you can write a prompt and have it generate an image for you. I wanted a plain old vanilla 30 year old guy with a business casual look. The headshot above is Will. He’s where I ended up. There were some lessons along the way. Here’s his virtual audition.
If you’re like me, the little twitches and other little affects along the way can be disappointing. The desire for a flawless interaction is natural but also almost impossible to achieve. The software still struggles to perfectly map the voice to the facial movements and it has a hard time providing human speech affect like when someone is confident.
The technology has gotten better over the last year and this visual is heads and tails above the quality of most of the Synthesia avatars.
Lessons Along the Way
Will actually started out as Brian. I wasn’t familiar with Hedra’s creative capabilities so I leaned into my Leonardo.ai credits and generated a handful of preliminary images that I wanted to test out. Leonardo.ai is around $10 for credits and all you have to do is drop in a prompt to start the process. Here is my original line up.

I imported one of the headshots into Hedra with some sample copy. The first output was ok. I won’t lie, I look at content like this a lot so maybe I’m more sensitive than others as to the facial tics, lags, etc. It was a good start but not overly impressive.
Whoops. It turns out voice selection is very important. He looks like a younger guy but sounds a lot like John Goodman. So I recreated him with a better voice.
The voice was better but as you can tell the Leonardo imagery is causing a lot of facial ticks. So to address this I tried using the same prompt on Hedra’s generative image creator. The updated options are below.

The image creator allows you to play with various levels of realism until you’re happy. Be careful though, you can easily click the wrong button and accidentally lose the avatar you finally got to liking.
Brian 1.2 is better, and having the character look directly at the viewer helps.
Brian 1.2 looked better but the voice wasn’t quite right. So, onto Brian 1.3. I decided to change up the copy a little too to see if it had any effect on the system’s performance.
It was the voice. I just couldn’t get used to it. Each voice has its own pre-assigned name. I’d started with Brian. After strolling through them I landed on a new voice named Will. I matched this new voice up to the next image the system had created and it began to feel much more natural. Natural is the key takeaway here. Don’t ask me why I picked the opening to the U.S. Constitution as the audition text. It has enough verbal complexity to really stress test the avatar. So I decided to take the experiment a step further.
You can get caught up in technical terms but the goal is to make viewers as comfortable as possible with what they’re looking at. Natural is the key to making that happen.
So Will 1.0 was born and he felt much better.
While not perfect, Will 1.0 was good enough. I felt like it was time to play around a little.
Having Fun With Hedra
Once you get to a place the video rendering doesn’t throw you off it can be fun to play around.
Good luck lampooning celebrities. If you want to deep fake Elon Musk you’ll have to find a different tool. Hedra, Synthesia and other applications are very wary of litigation so they place controls on what you can upload.

So what about a female? I decided to extend the talent competition to a variety of female avatars. I created Rachel using a rendering I stole from another creator on Leonardo.ai.

Leonardo is replete with lots of ultra-unrealistic representations of female beauty so I decided to select the least of the options. I liked the lifelike features this image offered so I decided to plug her into the system and see what happened.
There were definitely outtakes along the way. I tried mixing a more sultry female voice with a different name (Delila) and got this. :(
Creepy low talker aside, I was actually pleasantly surprised by how well this worked out… so much so I decided to experiment further.
Can We Make Them Sing?
A while back I started playing with a music generation app called Suno. You type in a prompt and it creates a song for you. The more you specify (i.e. music style, tone, topic, etc.) the better the output. I’d gotten it in my head to see if I could potentially create a modern rock opera similar to Queen or Pink Floyd. That has yet to materialize. But I did have plenty of experiments to plug into Hedra based on past tinkering.
I took a pop music song I’d generated and mixed it with the Rachel image and the results were pretty amazing. I’d created my own pop singer it seemed. While the facial expressions aren’t perfect at the start I was really surprised at how the A.I. picked up on the tone of the singing relative to Rachel’s facial expressions and head movement.
This was incredibly cool. I took an image created on Leonardo, a song I created on Suno and fed them into Hedra to create a short music video. This is what I talk about when I talk about learning about A.I.
Could I repeat this effort with Will? To answer that question I revisited his image and uploaded a song in the style of a classical opera piece I had created. I’d hoped to produce a piece along the lines of Mozart but ended up with something similar to Phantom of the Opera ala Andrew Lloyd Webber. Oh well.
I am now officially a synthetic music producer. And the quality of the facial mapping was so much better. I don’t know exactly why, but I suspect there’s a machine learning sentiment function that picks up on the tone of the audio in a way that influences the facial features. I saw this with both of Rachel and Will and not surprisingly the system seemed to work better with its own self-created image (Will).
Also, funny… I accidentally mixed them together. I can only imagine that twitch at the beginning was indignity. You pulled it off nicely though Will.
How About Clowns?
Clowns have a mixed place in our collective psyche thanks in no small part to Stephen King. You may remember Pennywise from IT. I plugged a prompt for Pennywise into Leonardo and got a nice mix of visuals. I then uploaded one of them to Hedra and selected a preset voice option called “Dr. Von Fusion.” It was creepy enough to match to Pennywise.

Pennywise plus Dr. Von Fusion propelled me from pop music producer to horror genre director.
You can see how the application struggles to adapt some of the image to what it sees as predictable facial features. But all in all still pretty amazing. This got me to thinking, what else could have have Pennywise do for us?
Virtual performance review at work?
Virtual apology for being a bad boyfriend?
We Just Learned About A.I.
If you recall my introduction explained how so much of the current A.I. dialogue locked most people out of the conversation. Yet here we are, having fun learning about topics including Natural Language Processing (NLP), Machine Vision, the Uncanny Valley and others.
You and anyone you know can participate in A.I. You just have to sidestep the predictable news cycles and engage with the medium.
Together all of this cost me around $30 and two hours of experimentation. You can find the resources as follows:
I encourage you to experiment and explore the creative boundaries A.I. tools offer. You won’t just learn, you will start to feel a sense of interest and association.
One Last Reading
This may have been the best of all the readings.